
What will it take for AI to change drug discovery?
Some thoughts on avoiding self delusion.

One of the most important empirical observations about modern drug development is Eroom’s Law: the finding, first articulated by Jack Scannell, that the number of new drugs approved per billion dollars of R&D spending has halved roughly every nine years. In other words, drug discovery has been getting exponentially less efficient, even as biomedical science has advanced dramatically. Sequencing is cheaper, computing is more powerful, high-throughput screens are faster, and the volume of biological knowledge has exploded. Yet we are producing fewer transformational medicines per unit effort than we did in the mid-20th century.
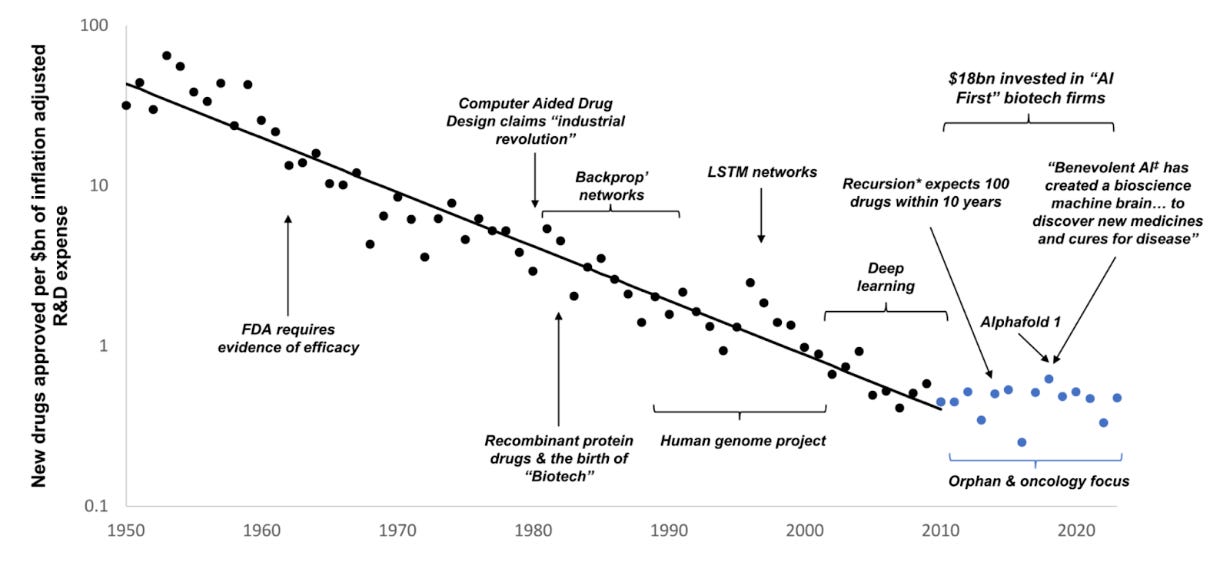
The latest wave of AI enthusiasm presents itself as the solution to this paradox. I am generally optimistic about the potential of AI to improve drug discovery. But it could just as easily become a net negative if it encourages two kinds of self-deception.
First, we may become so enamored with the sheer volume of new hypotheses it can generate that we forget the limiting factor is not hypothesis quantity but hypothesis quality, or, as Jack Scannell would put it, improving the predictive validity of our models. Generating more mid-PhD-level insights, the biomedical equivalent of “slop”, is not progress. It might be actively detrimental if it leads us to “clog” the clinical development pipeline.
Second, AI advancements may tempt us to overlook the irreplaceable nature of data derived directly from humans, leading us to invest more deeply in model systems that are misaligned with human physiology. We will pat ourselves on the back, happy we have trained a “bigger model” and forget what this was all meant to do in the first place. This has happened before, when, due to more stringent regulations, we switched from fast in-human experimentation (which dominated during the 60s), to the current paradigm dominating drug discovery, so-called “rational design”. More complex mechanistic insight, faster and higher dimensional science coincided with am overall decrease in efficiency of the pharma R&D enterprise, as explained at length in the The Rise and Fall of Modern Medicine.
Becoming captivated by our newest models may cause us to lose sight of a key bottleneck: without regulatory reform that enables easier generation of in-human, ideally interventional data, the evidence needed to truly advance the field will remain limited. I might sound like a broken record by now, but the core objective of the Clinical Trial Abundance project—accelerating and reducing the cost of obtaining human evidence—could be more catalytic than any individual technological breakthrough. Don’t take it from me, take it from Jack Scannell himself.
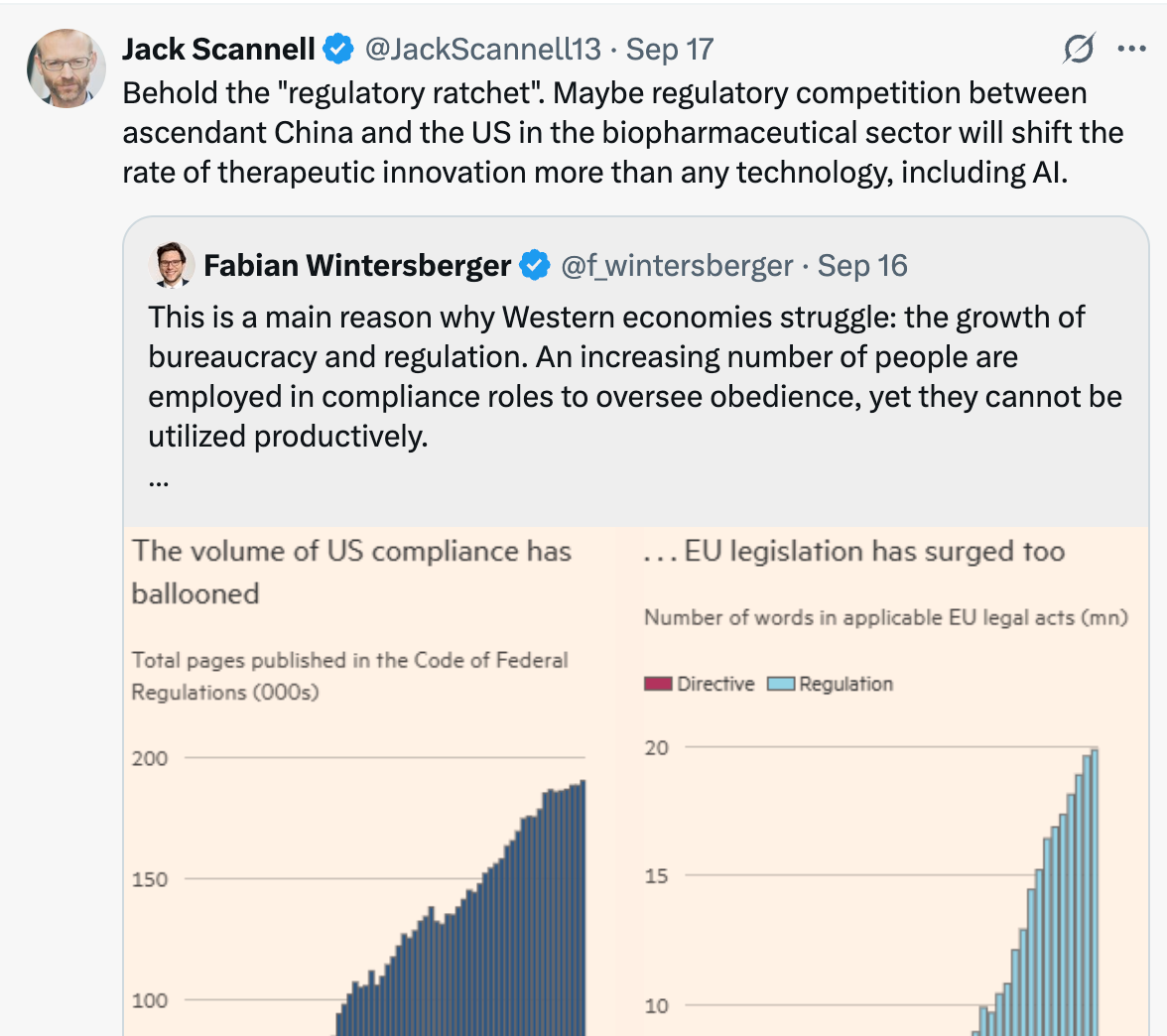
We do not need more hypotheses, we need better ones
Placing our hopes for future biomedical progress in the vague expectation that “AI will bail us out,” without first rethinking the kinds of data we generate and their impact on predictive validity, is no more rational than assuming that simply training more PhD students will increase pharmaceutical productivity. We have run the experiment of training more scientists and it has not worked out very well!
A common, implicit assumption in the current “AI-for-pharma” boom seems to be that the central bottleneck in drug discovery is the ability to find new drug candidates. The belief is that if AI can propose more molecular structures, explore chemical space faster, or mine literature more efficiently, it will unlock vast therapeutic value. Yet this narrative rests on a misconception, well captured here by Will Manidis.
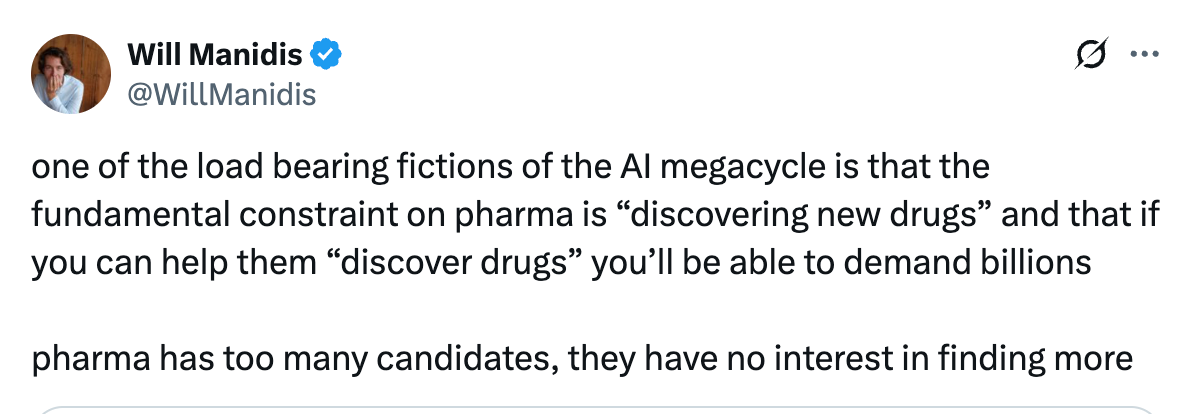
Pharma is not actually suffering from a shortage of hypotheses or potential drug candidates: they already sit on enormous compound libraries, thousands of unadvanced targets, and a backlog of mechanistic hypotheses derived from decades of molecular biology research. What remains a constraining factor is the ability to test them in humans. Given the high cost of clinical development programs (more than $1 billion on average), pharma must pick their programs judiciously.
We are currently very poor at predicting ex ante which therapeutic hypotheses will succeed in humans. Only about 10% of drug programs ultimately work, meaning we waste billions of dollars pursuing approaches that don’t translate. The core need is to improve our ability to identify hypotheses that are genuinely likely to produce clinical benefit—that is, to increase the predictive validity of our preclinical models.
However, existing AI systems are limited because they are not trained on the kinds of causal, dynamic, multi-scale biological data that would be required to replace or approximate in-human testing. They make use of the same data we have been generating for decades to inform our clearly not very successful strategies of defying Eroom’s Law.
AI has achieved its strongest results in biology in domains where the relationship between inputs and outputs is well-defined and heavily sampled, such as protein structure prediction or de novo antibody design. These areas benefit from large, high-quality datasets and clear optimization objectives, which allow models to learn efficiently. But the availability of these datasets is not accidental: we have good data because these were problems we already knew how to study and measure well. As a result, the applications of AI in these domains, while genuinely useful, mostly accelerate workflows that were already technically feasible. In other words, many current AI-for-biology successes are incremental, not transformational. AlphaFold, an impressive achievement, has not revolutionized drug discovery precisely because, for large classes of proteins, we are quite good at experimentally deriving structures.
This is nicely illustrated by a thought experiment asking what would have happened if Jim Allison (Nobel Prize Laureate for the discovery of immunotherapy) was given modern AI- based generative antibody tools in the 1980s. Likely, this would not have sped up the development of immune checkpoint blockade by more than about a year. The key reason is that the long delay wasn’t due to designing binders: CTLA4 was rapidly licensed and an antibody was patented within months. The slow part was figuring out which immune pathways could be perturbed safely and effectively in humans, and that required years of biological insight, animal models, immunology, and clinical experiments. AI cannot shortcut that at the moment.
However, there are cases where AI applied to protein structure prediction and de novo design directly addresses a genuine bottleneck — although such uses are at the moment the exception rather than the rule. NablaBio is one of my favorite examples of this1.GPCRs are one of the most clinically important target classes, but they have historically been extremely difficult to modulate—especially with biologics—because they are membrane-embedded, structurally dynamic, and adopt multiple signaling states. NablaBio’s platform generates large-scale functional data on GPCR signaling conformations and uses deep generative models to design ligands that selectively bind and stabilize specific receptor states. This enables state-specific modulation of GPCRs, something traditional experimental approaches cannot reliably achieve.
Nonetheless, even in the case of NablaBio, the core challenge it addresses is fundamentally a structural one: identifying and stabilizing specific protein conformations. This is a fine-grained intervention: highly precise, but still operating at the level of individual molecular interactions. What it does not do is resolve the broader biological and clinical context. The ultimate therapeutic outcome still depends on how those molecular perturbations propagate through complex cellular networks, tissues, and the dynamics of the human immune and physiological environment. Without clinical experimentation, we cannot fully predict these emergent effects. The true “Holy Grail” for AI in drug development would be the ability to anticipate such system-level responses with high fidelity.
Unfortunately, this is precisely where AI is the least well positioned to work well, at least at the moment.
We already have cautionary tales about how “more science” has not led to better practical results in medicine. The mid-1940s to 1970s, the so-called Golden Era of drug discovery, were defined by a close coupling of synthetic chemistry and direct human experimentation. Entirely new molecular classes, from antibiotics to antihypertensives, were rapidly trialed in patients. These advances generally did not arise from detailed mechanistic insight, but from iterative, empirical testing. In effect, the clinic itself served as the primary engine of discovery.
Once the obvious chemical scaffolds were exhausted and regulatory demands increased, making the clinical iteration harder, the field moved toward “rational design,” driven by molecular biology, genomics, and high-throughput screening. This approach promised greater precision and efficiency. Yet, despite these scientific advances, our switch to rational design coincided with a decline in pharma productivity. The new models often provided an illusion of progress: their conceptual elegance exceeded their predictive power, diverting researchers toward theoretical frameworks that did not reliably translate into clinical success.
Why? The underlying issue is the dominance of reductionist models. The core challenge in drug development, translating insights from isolated systems into organism-level therapeutic outcomes remains problematic. Across most disease domains, the available data are sparse, heterogeneous, and largely observational. Even the most information-rich resources, such as large-scale multi-omic datasets that combine genomic, transcriptomic, proteomic, metabolomic, and epigenomic layers, offer only static snapshots. They still miss the dynamic feedback loops, nonlinear behaviors, and stochastic processes that define living systems and ultimately determine therapeutic response. That's not say this type of data is useless or that we can’t derive insights from applying AI to it. Just that we must be careful about how we ultimately use it to increase predictive validity.
If we are not careful, AI could amplify the types of mistakes made during the switch to “rational design”. It is easy to produce endless hypotheses from the relatively poorly predictive data we have and fool ourselves with the impression of progress.
A positive example of progress on predictive validity comes from human genetics. Drugs whose mechanisms are supported by genetic variants have roughly a 2–3× higher probability of clinical success. This is because the “experiment” of perturbing a gene has already been run in humans, at physiological scale, over millennia. Genetics is the best example we have of science providing causal, in-human perturbation data without actually running clinical trials.
If AI is to help reverse Eroom’s Law, it must also be paired with a shift toward building and accessing the kinds of data that matter: directly human, mechanistically informative, and tied to real clinical outcomes. This is precisely why I am so keen on making clinical trials faster and more efficient. AI could even help with that (see here for an example of how)!
Making trials cheaper and faster should be pursued not as a replacement to AI, but as its much needed complement. Although I do hope we get catalytic improvements in technology, it is unclear when and if AI will ever replace in-human testing. On the other hand, the benefit from faster and cheaper trials is tangible, clear and will serve as an enabling complement to better AI models. Nothing to lose from pursuing it more aggressively!
AI won’t bail us out of the need for regulatory reform
A common misconception in current debates is that regulatory reform has become less important because AI will (magically?) accelerate drug discovery. The logic of such arguments goes something along the lines of: only 10% of the drugs we design succeed in trials. Clearly, the problem is that we are not good enough at designing drugs. Relaxing approval would just allow non-efficacious drugs on the market.
This view implicitly assumes that regulation mainly affects the final approval stage2. One reason for this misunderstanding is that regulatory reform is often associated with libertarian critiques that focus on lowering approval thresholds3.
In reality, the true bottleneck is earlier: the clinical trial pipeline, where we test hypotheses in humans. These trials take years, cost hundreds of millions to over a billion dollars, and are tightly regulated at every stage. Because this process occurs inside companies and out of public view, it attracts far less attention than the endpoint of approval. But when critics like Jack Scannell call for deregulation, they are largely referring to these phases. This is also where China has reduced barriers and is a large driver of why its biotech sector is accelerating. And it is precisely because of the low success rate of each individual attempt that we want to test more ideas, earlier!
AI can generate vast numbers of candidate mechanisms, targets, and molecules, but without efficient, affordable, and scalable ways to validate them in real patients, we risk producing a flood of low-quality or ungrounded ideas. This is the “slop trap”: more predictions, but no meaningful feedback loop. If we want AI to genuinely improve biomedical progress, we need to reduce the friction of running early and exploratory human studies. Making it easier to test more ideas faster would allow us to identify what actually works, discard what doesn’t, and use that empirical data to iteratively refine AI models.
No conflict of interest.
It is also wrong in that it ignores incentives for more investment, but that’s another discussion.
Relaxing approval standards would, in some cases, indirectly reduce the clinical trial burden, but these details are often lost from conversations.
Largely agree with the thesis here, worth noting that transcription factors (intrinsically disordered, historically considered “undruggable”) may fall under the same category of GPCRs where we really are limited by drug candidates and AI could help. Also many isolated cases, consider suzetrigine, breakthrough pain medication where a large part of the difficulty was the excruciatingly difficult med-chem optimization. Actually now that I think about it, what percent of the proteome is currently considered druggable? There’s a plausible world where we have many hypotheses and possible drugs, but they’re systematically concentrated around kinase inhibitors or whatever, so there is tons of low hanging fruit in the biology sense that better AI drug design could help access
The problem with generative AI is that it often gets simple things wrong. It can generate a picture of a dog with five legs. The geometry of a drug molecule is very critical! What if the generative model generated a target molecule with the wrong number of geometric features like the number of atoms in a molecule ? Not good 😊