
Why haven't biologists cured cancer?
It's not because they're not good enough at math

“We were promised a cure for cancer and all we got are so-and-so improvements in five-year cancer survival rates” would be a fair thing to say about progress in biomedical sciences in the last few decades. And cancer is one of the disease areas where we have done pretty well, relatively speaking. If we look at Alzheimer’s, the situation is much worse: up until 2021, we had gone for 20 years with no new drugs - and even the approved ones have marginal effects1.
The big question is: Why? A common explanation is that biology might simply be too hard for us to manipulate successfully. Humans have come up with very clever solutions to defeat all these ailments, but despite our ingenuity, we simply cannot match what has been shaped by millions of years of evolution. Another explanation is that this is, to use a very online term, simply a “skill issue.” It’s not that biology itself is too hard, we’re just not being smart enough about understanding and manipulating it.

A version of the second theory that I am hearing more and more is that biology suffers from a talent problem. This is what Peter Thiel suggests in one of his interviews: that the smartest people go into “harder” sciences, leaving matters as important as whether we will be able to extend human lifespan substantially in the next decades in the hands of subpar people, the ones who could not do math well enough. His interviewer, Eric Weinstein, pushes back a bit against this: after all, molecular biology itself was in large part founded by physicists. But Thiel then appeals to some of his earlier comments about the lack of polymaths in academia and argues that today’s fields are too siloed for a mathematician or physicist to easily transition into biology.
The more optimistic one is that the culture is just broken. We've had very talented people go into physics. You go into biology if you're less talented. You can sort of think of it in Darwinian terms. You can think of biology as a selection for people with bad math genes. You know, if you're good at math, go to math, or physics, or at least chemistry, and biology we sort of selected for all of these people who are somewhat less talented. So, that might be a cultural explanation for why it's been been slower progress.
I disagree with this theory and lean much more towards the “Biology is very complicated” explanation. Biologists are less good at math than other scientists, but that’s because there are many areas of biology, and productive areas at that, that do not require that much of it. What’s more, when such skills are needed, it is fairly easy for people trained in a more quantitative science, like physics, to transition into biology. And the interest is there: when my friends from such disciplines want to apply their skills to a more “world of atoms” field, they inevitably lean towards biology. I am not arguing that everything is optimized to perfection. There is a case to be made that it should be much easier for a mathematician to become a biologist2. It’s also self-evidently true that any intellectual field will benefit from increased intellectual capacity in its workforce. My argument is simply that this is not the main rate-limiting step in biological progress.
I think the best way to illustrate my points is to look at the history of a specific field, genomics, where there was a lot of will to apply mathematical principles, where this will materialized, and, where top scientists awarded with status and directing large-scale initiatives were mathematically trained. Each and every time, genomics stumbled upon the same problems biologists have struggled with forever: biology is just very messy and hard. The complexity and unpredictability of biological systems limit the effectiveness of pure intellect and sophisticated predictions. What's more crucial is our ability to rapidly test and validate our hypotheses through experimentation. Faster feedback loops can be achieved in basic scientific research through improved experimental methods. In the medical field, accelerating progress will involve streamlining clinical trials both in terms of time and costs.
Genomics: a case study
When I take a walk on the outskirts of Cambridge, I sometimes stumble upon “the BRCA2 cycle path”, a road painted in stripes of four colours, according to the genetic sequence of BRCA2 – a gene which, when mutated, causes significantly increased risk of breast cancer. It’s a celebration of the achievements of British scientists and the central role Cambridge in particular has had in the Genomic Revolution. At the time, in 1994, establishing the identity of BRCA2 as the gene responsible for increased susceptibility to breast cancers, was a monumental feat3. This work was done before the publication of the Human Genome, so researchers were fishing semi-blindly among billions of letters of unexplored genetic code.

Fast forward to 2024 and one can get their entire genome sequenced for as little as $250. This includes the identification of potentially deleterious mutations in BRCA2 and hundreds of other cancer-predisposition genes we have discovered since. We have come far in 30 years: from struggling to find the identity of one disease causative gene with relatively rudimentary methods, to regularly reading and interpreting entire genomes made of around 3 billion base pairs4 each.
In some ways, I could end the essay here: to regularly read, analyze and store such large amounts of genetic data, it’s obvious we must have integrated quite a lot of mathematical and computing principles in biological workflows. Yet these technical achievements have not been matched by a comparable increase in biological understanding and even less so by a revolution in medicine. Clearly, throwing our technical armamentarium at biology is not enough: there is something intrinsically hard about dealing with the “messy, wet” world of biology, as a tech friend of mine likes to call it. The answer then must be closer to “Biology is complicated” than to “We do not have enough math in biology.” At this point some bioinformaticians might quibble that the computational part of biology is still inefficient for this and that reason. Sure, that might be the case. If diffusion from mathematical to biological sciences would have been perfect, maybe we would have reached our current state of knowledge in 2020 instead of 2024 and so on. But the Revolution still wouldn’t have been here.
A proponent of the talent hypothesis might respond that, although quantitative scientists have entered biology in large numbers and brought mathematical tools with them, the intellectual boundaries of the field are still largely defined by biologists. As a result, these quantitative researchers are often confined to support roles, with limited influence over the direction of the science. In this view, biology has not fully captured the potential value of this talent influx, because the future of the field continues to be shaped primarily by “classical” biologists rather than by those introducing fundamentally new ways of thinking.
As my examples will later show, math-trained scientists who later made the switch to biology, like Eric Lander, Aviv Regev, Richard Durbin, have been very important voices in the field of biology and some have achieved positions of extreme influence beyond academia.

The hope for a digital science
A layperson transported from the 90s in today’s world would not be that shocked by our medical advancements, in the same way a Geneticist from the same era would be in awe of just how much data we are able to process. So how did we get here?
On June 26, 2000, the International Human Genome Sequencing Consortium announced that it completed a draft of the sequence of the human genome — the so-called “genetic blueprint for a human being.” This was, at the time, a tremendous achievement and the culmination of a more than a decade long effort. To mark the importance of the moment, President Bill Clinton held a ceremony at the White House to announce the achievement, in front of a gathering of ambassadors, scientists, company executives, disease advocates and journalists. Hopes for a revolution in medicine were high.

Tremendously useful as the Human Genome might have been5, the revolution did not quite materialize: not 14 years ago, when NBC ran an article with this headline, and not today.

For sure, progress has been made: we are able to prenatally screen against deadly & debilitating diseases, particularly if they are monogenic6. Five-year cancer survival rates for many cancers have increased, and genomics has played a part in it. It’s also a part of so called “personalized mRNA cancer vaccines”, which show promise in diseases like pancreatic cancer, which at the moment suffer from abysmally low survival rates. Genomically-supported drug targets are two times more likely to get approval in clinical trials. But to many, this does not quite look like a Revolution.
And, as pointed out before, insufficient integration of mathematics into biology is hardly to blame for this. If anything, genomics as a field was imbued, from pretty early on, with the desire to digitize biology, to nail it down to a “code”, much like software itself. This is evident from the terminology the field used: “Decoding the Book of Life” said the banner behind President Clinton. As well as the ethos of those in the field. To quote someone mathematically minded that I have much respect for: “I like working in genomics because, unlike most of biology, it’s much less messy, much more digital.” It’s also in the name: genomics derives from genetics but added the -omics at the end, a suffix that in biology has come to signify studying large numbers of molecules at the same time: the whole genome, not just one gene at the time, as had been done in classical molecular biology before. Where molecular biology is descriptive and reductionist, genomics is code and big data.
This mentality resulted in a rapid integration of methods from computing and mathematics to study genes. Even before the publication of the human genome, when experimental methods became advanced enough to generate the necessary data6, mathematically trained bioinformaticians like Richard Durbin were designing computational tools to move beyond classical genetics and study genes in a more systematic/computational fashion.7 This type of work only intensified after the publication of the human genome, and was obviously intensely exploited as part of the human genome effort itself. All this is not to say that there was no friction and ego battles between the data-minded genomicists and the more “classical biologists”, especially those studying proteins8, who had pretty much reigned supreme over the field of biology for decades. Yet, one must recognize that the most software-like part of biology was afforded great status and resources, with the President himself announcing the completion of the human genome: a kind of official honour that was afforded to few other biological fields.
It’s complicated
So what happened? Why didn’t the publication of the human genome, “the code of life”, solve all of biology?
In some ways, The human genome raised more questions than it answered. For example, it showed that humans have about as many genes as some of the simplest organisms, like worms (C Elegans). Yet we are clearly more complex than worms. How was that possible? Another perplexing finding was that most of the human genome was composed of so-called “junk DNA” — that is, DNA that did not code for any protein. The central dogma of Biology says that DNA codes for RNA, which in turn codes proteins, the molecules that carry out most of our cell’s functions. So what was all the DNA that was not coding for any protein doing there?
One explanation among many is: epigenetics. DNA is just part of the story when it comes to how a cell behaves. One can think about it this way: all cells in a human body share the same DNA, yet some are muscle cells, others are skin cells and so on, each carrying a very specific and differentiated role. This is possible due to chemical marks that sit on top of DNA, or the proteins that DNA is wrapped around, and help specify which genes are turned on and off in which type of cell. Our ability to map these epigenetic marks lagged behind that of sequencing DNA. But, in time, researchers developed methods to sequence (or read) these epigenetic marks at scale9, in the same way they had done for DNA itself.
With these methods came the idea behind ENCODE, a sort of Human Genome Project but for epigenetics, that ended in 2012: what if we could map all the epigenetic marks in different cell types in the same way we had done for the genome? A key player in setting up encode was Ewan Birney, now head of the European Institute for bioinformatics, and the aforementioned Richard Durbin’s PhD student. ENCODE was again the result of a software-inspired data-driven mindset. And, much like the human genome project itself, it produced a valuable reference dataset for researchers to use. Yet it has not revolutionized biology. Because, again, biology is more complicated than this.
As a starter, it turns out that we do not even know for sure what most of these epigenetic modifications do — take for example DNA methylation, which I happen to study. The standard wisdom is that DNA methylation represses (or turns off) the expression of genes, something that was inferred mostly via large scale correlative studies10. If DNA methylation was causally repressive, one would expect that artificially inducing DNA methylation would lead to ubiquitous gene repression. Yet, when better experimental methods were developed to achieve such a perturbation in cells and test this hypothesis, it turned out that about half of the genes whose promoters were artificially methylated behaved in an unexpected fashion: either not changing expression at all or becoming activated. As the authors of the article themselves say: “We find that transcriptional responses11 to DNA methylation are highly context-specific.” Again, biology is complicated.

Many Human Genome Project, ENCODE- like inititatives, focused on sequencing at scale and inspired by the same desire to systematize biology, have existed since then. For example, efforts to catalogue and characterize all mutations in human cancers, like The Cancer Genome Atlas and the Cancer Genome Project. The former was spearheaded by Eric Lander, trained as a mathematician, who was also the 11th director of the Office of Science and Technology Policy and Science Advisor to the President. We have not only managed to map cancer mutations: by applying computational methods from evolutionary biology (and ultimately from mathematics), we are able to pinpoint which ones are causative, and which ones are under neutral selection, distinguishing passengers (which we do not care that much about) from so-called “drivers.”
One of the hopes in these efforts is that we would get personalized, genomically targeted therapies for cancer: if someone has mutation X driving their cancer, we would target a therapy to that mutation specifically. Yet, in practice, this strategy has been somewhat underwhelming. We do have some genomically targeted therapies, but they work in a minority of cancers: as of 2020, an estimated 7% of cancer patients were benefiting from genomic medicine at all. One complication for genomically targeted therapies is that, even if you create a therapy targeted to certain mutation, the tumour has usually already gained the ability to quickly evolve and evade your therapy through the acquisition of other mutations. Where genomics has showed the most success in guiding therapies is actually when it has been combined with novel wet-lab derived techniques (e.g. mRNA technology & delivery methods for this), which have nothing to do with better mathematics. An example of such a success are personalized mRNA-based cancer therapies, where the mRNA is tailored to mimic the mutations present in one person’s cancer, and stimulate their immune system to attack their tumour. This approach has shown promise in early stage Phase I trials for pancreatic cancer.
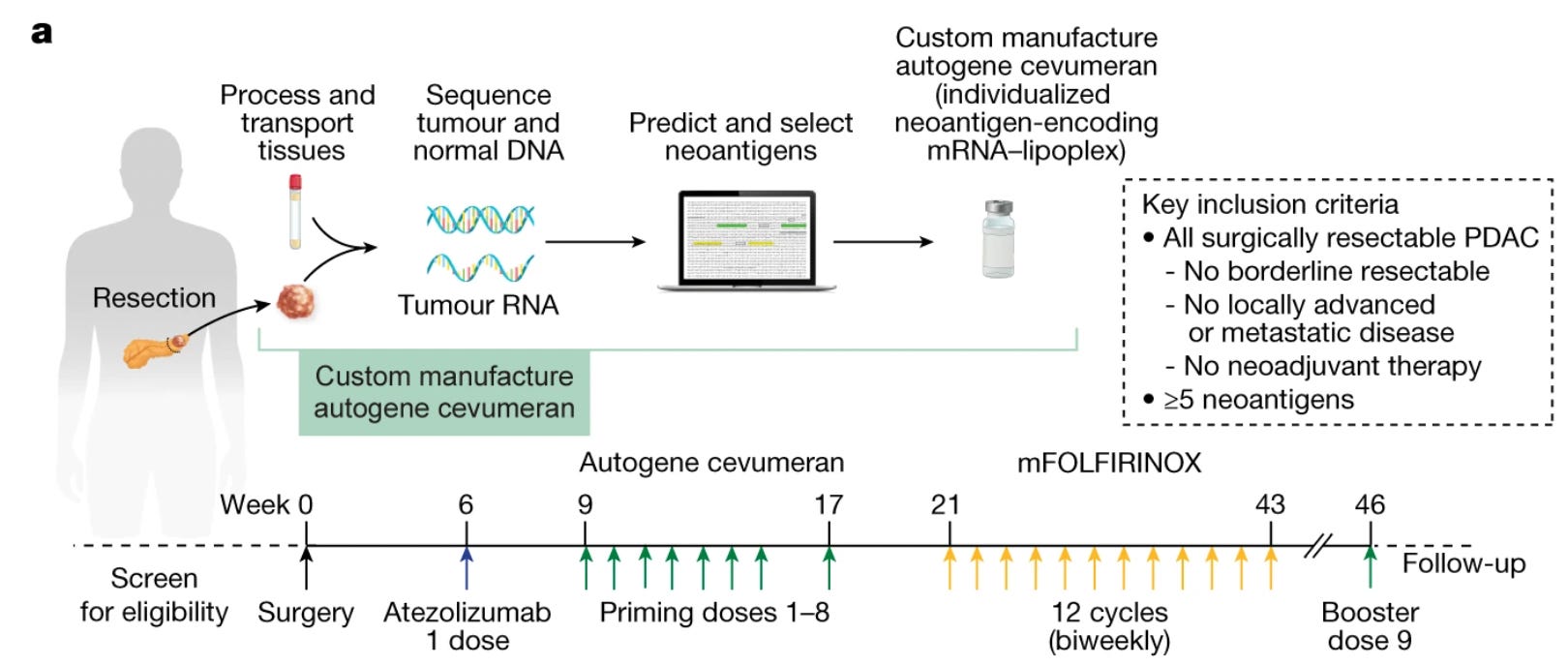
Biology is complicated. Now what?
“We need to remember that while mathematics is the art of the perfect and physics the art of the optimal, biology, because of evolution, is the art of the satisfactory”
(Sydney Brenner, Nobel Prizer Winner)
That biology is complicated is not a reason to think we cannot optimize anything about the way we do science. And of course, talent is important, although perhaps more relevant than mathematical ability itself are certain personality traits, as I argue in my essay The Weird Nerd comes with trade-offs. But, fundamentally, if I had to pick just one factor that I think is holding biology back, I would say “long feedback loops”, as argued in this piece by Stephen Malina. Baked into this assertion is the premise that we cannot simply “understand” biology from first principles, in the same way we do for physics, and all we can hope for is iterative cycles of experimentation. Thus, the faster these cycles, the more surface area we will cover. In a domain like biology, we should expect diminishing returns from extra intelligence and better predictions, with a much bigger bottleneck being the speed with which we can test these predictions12.
One of the reasons innovation in areas like machine learning seems to happen so much faster is that one can iterate and carry little “digital experiments” at a much faster pace than one can do in biology, where one has to wait for results from laborious and slow experiments. Looking at feedback loops in the area of medicine, they are even slower. To figure out if a drug works or not, one has to wait for what is approximately a decade of pre-clinical validation followed by clinical trials. Given that 90% of therapies that advance into human trials fail, information from these human trials is particularly important. If one considers the difficulties in realizing the promise of “genetically-targeted” cancer therapies, mentioned in the previous section, a lot of them are about feedback loop speed from ideation to results in humans:
Genetically engineered mouse models have provided irrefutable evidence of the role of mutated genes in cancer development and maintenance and are important models for assessing drug sensitivity and resistance. However, modeling disease in living organisms is expensive, complex, and time-consuming, limiting its use for screening thousands of genomic alterations for therapeutic potential […] Ultimately, evidence of the clinical actionability of a genomic alteration must come from large, late-phase trials that include many patients with the alteration of interest.
(from this review)
Feedback loops in medicine can get even slower than that. If the first therapeutic in a new class fails or causes a severe side-effect, this will chill investors and companies towards that entire class and set the field back years or even decades. That’s exactly what happened to the field of gene therapy, a domain scientists and investors were excited about all throughout the 90s. The death of Jesse Gelsinger in 1999, a patient treated with an adenovirus therapy, put a halt to progress in the field and set research back significantly. Investment and general interest in this area declined sharply. It would take another 18 years for gene therapy to score its first definitive success, when the FDA approved Kymriah in 2017 for a form of blood cancer.
The speed of feedback loops also shapes incentives in a field: as I argue in another one of my pieces, it’s plausible that the exceedingly long timelines it takes to develop a drug lead to misaligned incentives within pharma companies, with corresponding decreases in efficiency:
One of the potential sources of inefficiency in the biopharma sector is downstream of the fact that drugs have such long development timelines, which are seen as unusual by those working in other industries. Although the total amount of time it takes for a compound to go from identification to approval varies a lot, a commonly cited median figure is 10-15 years. But humans (and their ambitions) operate on shorter timelines. This misalignment can lead employees to push assets that boost their careers in the short-term, even if those assets don't benefit the company or patients in the long run. After all, a drug's real results might only surface a decade later!
The future
If feedback loops are so important, what does the future of the field look like? Overall, I am bullish on biology and more bearish on medicine. The reason is simple: we are getting better and better at doing large-scale, so-called multiplexed experiments, where many outcomes are measured in the same experiment. Some believe that the future of biology lies entirely in iterations of these large scale experiments, followed by feeding the results into AI models and refining predictions. This is what an increasing number of biologists across academia and the private sector are attempting to do. For example, Dyno Therapeutics is a start-up that has developed a platform to carry out massive multiplexed experiments to improve the tissue-specificity and efficacy of gene therapies. The results from these experiments are fed to ML algorithms that recommends better proteins to try out in the next cycle, in an iterative fashion.

The reason why I am (somewhat) bearish on medicine is that there are signs feedback loops are getting slower and also fewer in number. Clinical trials, the main avenue through which we can get results on whether drugs work in humans, are getting more expensive. The culprits are so numerous and so scattered across the medical world, that it’s hard to nominate just one: everything from HIPAA rules to Institutional Review Boards (IRBs) contribute to making the clinical trial machine a long and arduous slog. An increase in clinical trial costs will mean that for the same amount of money, there will simply be less of them and consequently, less feedback. There are some reasons for optimism too. The COVID pandemic showed us that some high-quality trials are much cheaper than others - the RECOVERY clinical trial in the UK that discovered steroids cut COVID-19 deaths by ⅓ was much cheaper than traditional trials. A challenge for policymakers will be learning from this experience and implementing RECOVERY-like strategies across a larger number of clinical trials.
One could also argue that, even if clinical trials are getting more expensive, we can always just invest more in drug development. After all, it’s such an important area. Unfortunately, all signs point towards the opposite being true in the near future. The current political trend is that of regulating down drug prices, via bills like the Inflation Reduction Act. In a recent paper, economists Ariel Pakes & Kate Ho attempt to estimate the impact of such policies and conclude:
Our calculations indicate that currently proposed U.S. policies to reduce pharmaceutical prices, though particularly beneficial for low-income and elderly populations, could dramatically reduce firms’ investment in highly welfare-improving R&D. The U.S. subsidizes the worldwide pharmaceutical market. One reason is U.S. prices are higher than elsewhere.
This means that, if US lowers spending on drugs and other countries do not pick up the tab, we will have less investment in drug development. If this does happen, the only hope is for us to get so good at biology that the therapeutic candidates we will be advancing into clinical trials will succeed at much higher rates than they do at the moment, making up for the decrease in the number of such trials. Basically, we would rely entirely on positive spillovers from better biology.
The trends in terms of medical feedback loops do not look good. If these trends hold true in the near future, we should expect more and more expensive trials with less and less money going into clinical trials, as well as in pharmaceutical R&D more broadly. An interesting observation is that the speeding up of feedback loops in pre-clinical biology has mostly been an emergent, undirected process, born out of the efforts of thousands of scientists across academia and private industry. On the other hand, the slowing of feedback loops in medicine will have largely been the result of policy decisions. It might be that science is the field that’s actually working best at the moment!
Acknowledgements: Thanks to Stephen Malina and Willy Chertman for helpful comments
Aducanumab’s approval in 2021 was itself contested, with many considering the evidence incredibly poor. This skepticism proved to be warranted: Biogen discontinued Aducanumab this year. Some have argued that the FDA approved this drug in order to bolster the confidence in a field that had only seen failures for a long time.
In general I am of the opinion that people should be able to move more between academic disciplines.
The scientist who coordinated this study, Michael Stratton, would go on to be the Head of the Sanger Institute in Cambridge and receive a knighthood. 25 years on, his discovery of BRCA2 is still one of the main things that is mentioned in articles about him, despite him having gone on to publish widely (e.g. his lab would discover cancer mutational signatures) and direct the Cancer Genome Project and other initiatives.
Think of base-pairs as the letters of DNA. There are 4 of them: A (Adenine), T (Thymine), C (Cytosine) and G (Guanine.)
I, and most scientists, use it everyday in one shape or another.
This mostly refers to sequencing, which is the experimental method through which the sequence of letters in DNA becomes readable and interpretable to humans. The first version of sequencing was developed in 1977 by Fred Sanger.
See for example intro to this book by Richard Durbin describing his forays in the early 90s into the world of probabilistic modelling for DNA sequence analysis (neural nets make their appearance here, too.)
“At a Snowbird conference on neural nets in 1992, David Haussler and his colleagues at UC Santa Cruz (including one of us, AK) described preliminary results on modelling protein sequence multiple alignments with probabilistic models called 'hidden Markov models' (HMMs). Copies of their technical report were widely circulated. Some of them found their way to the MRC Laboratory of Molecular Biology in Cambridge, where RD and GJM were just switching research interests from neural modelling to computational genome sequence analysis, and where SRE had arrived as a new postdoctoral student with a background in experimental molecular genetics and an interest in computational analysis. AK later also came to Cambridge for a year. All of us quickly adopted the ideas of probabilistic modelling. We were persuaded that hidden Markov models and their stochastic grammar analogues are beautiful mathematical objects, well fitted to capturing the information buried in biological sequences. The Santa Cruz group and the Cambridge group independently developed two freely available HMM software packages for sequence analysis, and independently extended HMM methods to stochastic context-free grammar analysis of RNA secondary structures. Another group led by Pierre Baldi at JPL/Caltech was also inspired by the work presented at the Snowbird conference to work on HMM-based approaches at about the same time.”
When I was an undergraduate at Oxford, I mostly took courses in the Department of Biochemistry, a very old and classical Department, taking pride in associations with people like the Nobel Prize winner Dorothy Hodgkin, who discovered the structure of insulin while at Oxford. My lecturers and professors were often not entirely excited about my desire to move into Genomics, and still mostly saw it as a “bastard field.”
I am referring to Bisulfite Sequencing for DNA methylation, Chromatin Immunoprecipitation for histone modifications, Hi-C for 3D genome analysis and so on.
there are also some early experimental studies pointing in this direction.
Transcriptional response refers to whether a gene is turned on or off.
Another macro-level argument for “Biology is complicated” is that we have had different success rates based on therapeutic area, that seem to track the intrinsic level of difficulty of the problem. It’s reasonable to believe that there isn’t much difference in the intelligence of people studying Alzheimer’s versus cardiovascular disease yet the differences are large in terms of success.
Overall, cardiovascular disease and diabetes have seen the most successes. For heart disease in the last 20 years we have had: PCSK9 inhibitors, ezetimibe, bempedoic acid. And much earlier than that, statins, which have been among the only successful preventive drugs: Primary prevention with statins was associated with 17% reduced risk of all-cause mortality. Interestingly, through different mechanisms, they ALL target the same pathway - lowering LDL cholesterol, which is a pathway that is straightforward and that we understand. For heart disease we also have a good surrogate endpoint (LDL cholesterol) that got validated through clinical trials and leads to shorter feedback loops.
Cancer is somewhere in the middle: although we have studied it quite a lot and have decent models of it, it’s also a particularly nasty disease, with its unique ability to evolve and escape treatment. Alzheimer’s and all brain afflictions do much poorly, which maps with how hard it is to not only model, but also target the brain. Finally, ageing is the worst. Here we lack good surrogate endpoints (or clear endpoints at all), good models, and the feedback loops are obviously the longest, in both model organisms and in actual humans.
Agree with your conclusion! Neuroimaging/neuroscience is another field in which there are lots of physicists and engineers but not much acceleration of progress.
I think another thing that we don’t take into account is that we have so many (necessary) ethical things in place to protect human trial participants. If we had fewer restrictions, we could probably fly through far more options, but at a greater human cost. Hence why we have so many things that work on mice: as much as I hate to say it, we don’t really care what the impact on them is outside of what it means to us.
It also takes a huge amount of time for a drug to be approved, in part because of large wait times on applications.
While I would love for it to be as simple as ‘do more maths’, anyone anywhere near medical research knows it really isn’t that simple 😅